
Pandasのデータ分析で重要なピボットテーブルを使って、
データの関係性を可視化していきます。
目次
前回までのおさらい
>>>【Pandas入門】groupbyを使ってデータのまとまりをつくる|Anacondaでデータ分析
前回は、Pandasを使って、こんなデータを作成しました。
以下はとあるq1のスコアを可視化したグラフです。
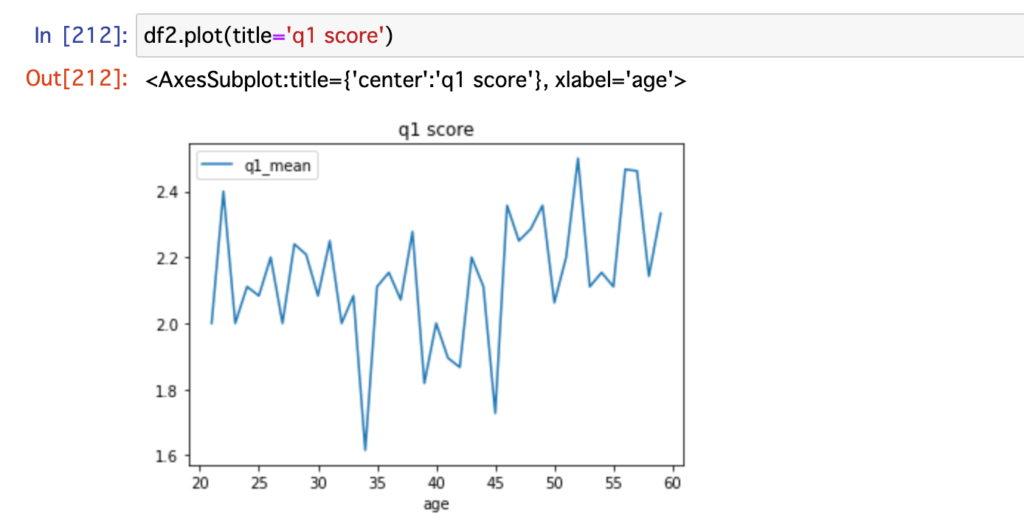
でも、年齢別のq1の平均値が分かりましたが、性別ごとの比較も知りたいですよね。
ちなみに以下が、グラフのもととなる表です。
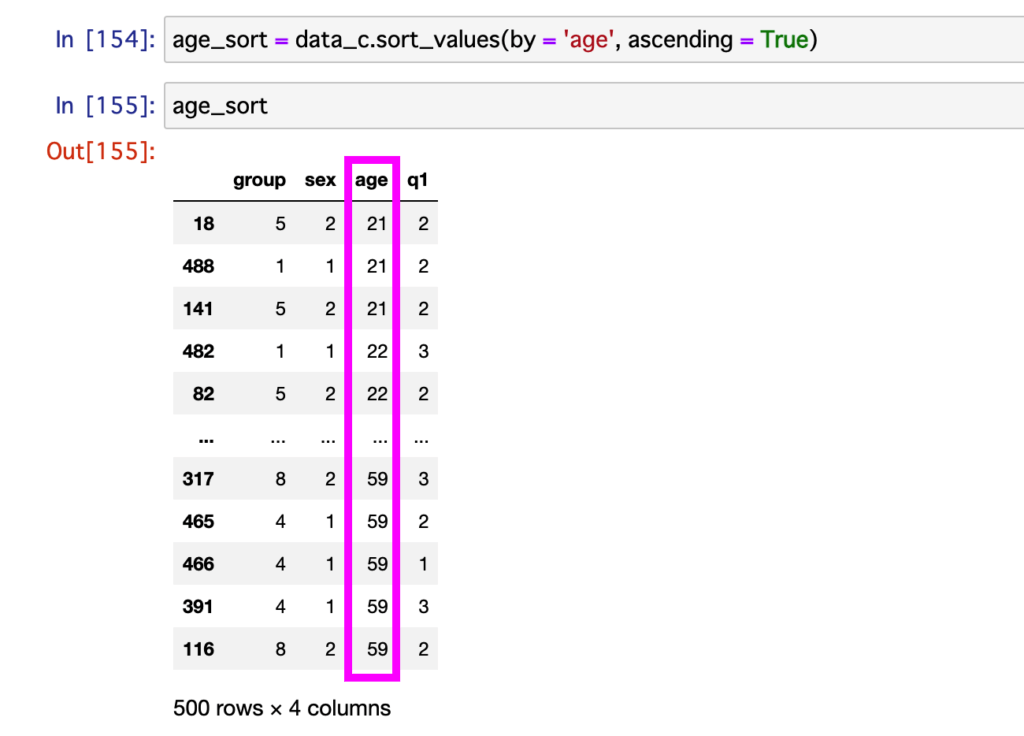
これだと、年齢しか整理できてないね!
年齢だけじゃなくて、性別についても整理するってことね!
ピボットテーブルを使って、データの整理
前回は、ageだけをソートしましたが、今回はsexのカラムもソートします。
前回と方法は同じなので、コードは割愛します。
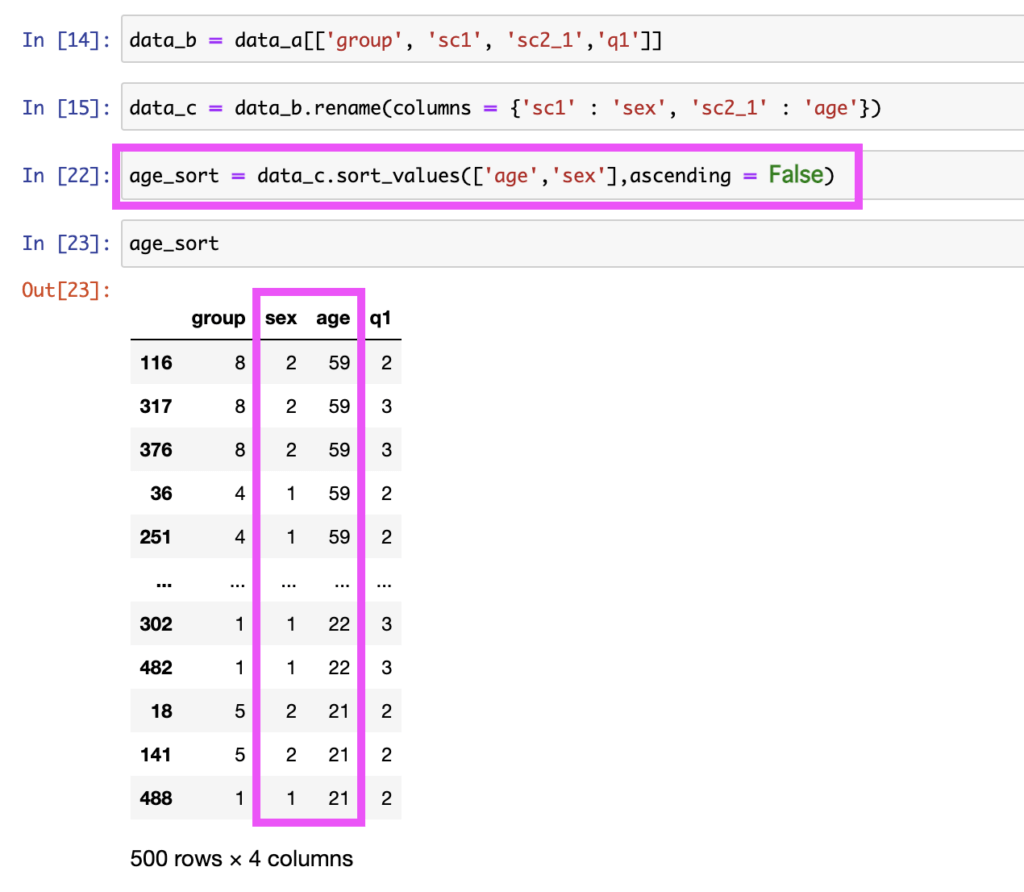
今回は、groupbyの引数に、ageだけでなく、sexを追加します。
age_group = age_sort.groupby(['age','sex']).q1.mean()結果は以下になりました。
今回は、年齢と、性別の2つの軸でデータが整理することができました。
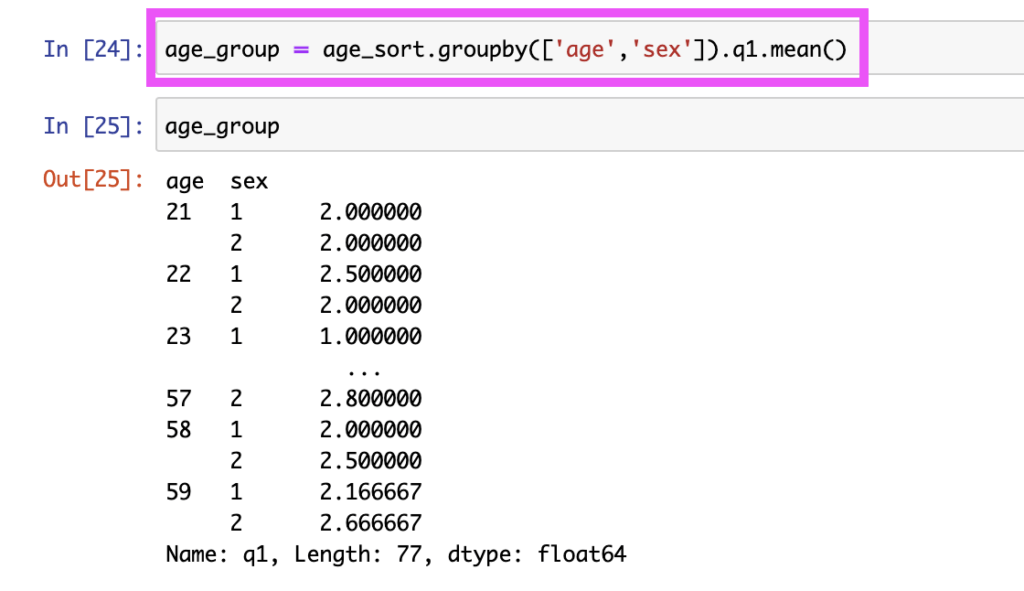
続けて、前回同様、q1の名称を、q1_meanに変更しました。

これをさらに整理するために、ピボットテーブルを使用します。
pivot_tableの実行
やり方は以下です。今回は、df3という新しい表を作成しています。
df3 = df2.pivot_table( index='age', columns = 'sex')df3実行結果は以下です。
※画像の表は途中までです。
列が性別(ここでは1と2)に分かれて、とっても見やすくなった!
うん!ピボットテーブルを使ったおかげだね!
データの可視化
最後に前回同様、データの可視化をしていきます。
df3.plot()結果は以下です。
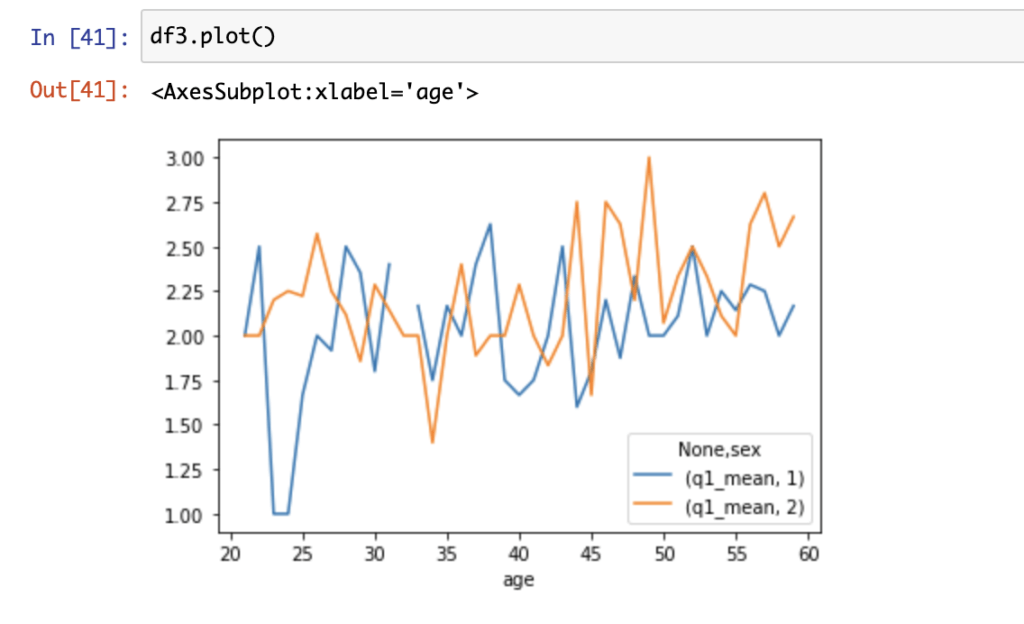
無事に、性別ごとのグラフが表示できました。
これを見ると、q1スコアの性別による相関関係の薄さが見てとれます。
まとめ
今回は、データ分析の肝となるピボットテーブルを初めて実行してみました。
ピボットテーブルを使うことで、クロス集計が簡単にできるので、
覚えておくだけで何かと重宝するテクニックの一つです。


![Anaconda Proceed ([y]/n)? の対処法の巻](https://clione33.online/wp-content/uploads/2022/04/anaconda-proceed-y-or-n.png-300x158.webp)





コメント